
近接マップリードテクノロジーに関する見解
近接マップリードテクノロジーに関する見解
Rady Children's Institute for Genomic MedicineのDr Stephen F. Kingsmoreが、近接マップリードテクノロジーと、それが希少な遺伝性疾患の迅速な全ゲノムシーケンス(WGS)に与える潜在的な影響に関する見解を述べます。
TruPath Genomeを支える近接マップリードテクノロジーを使用して、長距離情報によりショートリードゲノムシーケンスを強化します。

イルミナシーケンサーは、ゲノムマッピング法を大幅に進歩させ、研究者がヒトゲノムの大部分で高精度なカバレッジを達成する手助けをしてきました。1しかし、ごく一部のゲノムでは、ショートリードをリファレンスゲノムにマッピングすることは依然として困難です。これらの課題は、主に反復性または低複雑性の領域、高いシーケンス相同性を持つ領域、または大きな構造的変異で発生します。
近接マップリードテクノロジーは、ゲノムのマッピング困難な領域におけるマッピングの改善、遺伝的バリアントの超長距離フェージング、構造的バリアントの検出の強化を提供します。

近接マップリードテクノロジーは、フローセル上でのライブラリー調製と、近接するナノウェルのクラスターから得られる近接情報を取り込む新しいインフォマティクスを活用し、長距離ゲノムの洞察を生成します。TruPath Genomeアッセイで利用可能な、独自の極めて簡略化されたワークフローは、元となる大きなDNAテンプレートとそこから得られる短いシーケンスリードとの関連性を維持します。
近接マップリードテクノロジーは、包括的なゲノム解析を提供する独自のワークフローを使用しています。
フローセル上でのライブラリー調製により、サンプルからシーケンサーまでのWGSワークフローを最もシンプルにします
NovaSeq X シリーズのXLEAP-SBSケミストリーは、高い精度と1ランあたり2~16サンプルという拡張性を提供します
クラスター近接解析により、優れた長距離情報が明らかになります
マッピングの強化により、困難な領域を解明し、より精度の高いゲノム情報を提供します
新しい手法により、大規模な構造的再構成の検出精度が向上しました
近接マップリードテクノロジーでは、トランスポゼースが固定化されたフローセルに、標準または高分子量法で抽出されたDNAを導入します。DNA断片は、タグメンテーションと呼ばれるプロセスを通してナノウェルに捕捉され、シーケンスを行います。近接ナノウェルは、大きなDNA断片を捕捉することにより、コンステレーションのようなパターンを生成することで、DRAGEN Germline解析による新しいアルゴリズムを用いてクラスターを元の断片にマッピングすることができます。これにより、ショートリードシーケンスの実績のある精度や長距離ゲノムの洞察が組み合わさり、マップ困難な領域のマッピングを大幅に改善し、構造多型の検出力を高めるほか、超長距離のフェージングを可能にします。

図1a:コンステレーションパターンの上面図
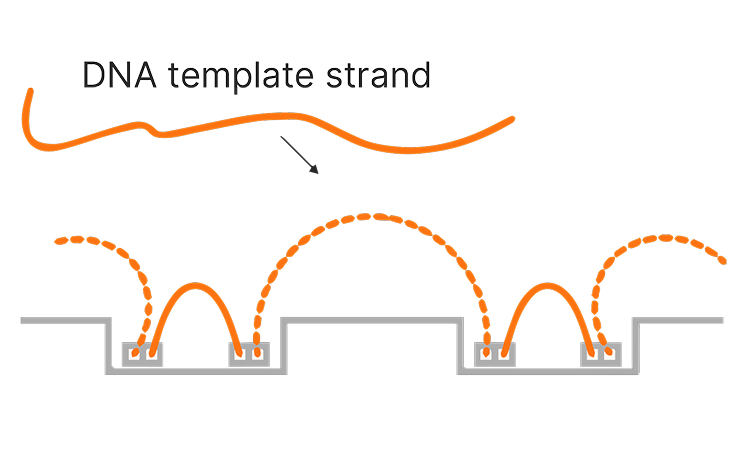
図1b:コンステレーションパターンの側面図
図1:DNAがコンステレーションパターンでフローセルに結合。上面図は、タイルのごく一部であり、フローセル全体のDNA鎖を示しています。側面図は、フローセル上でタグメンテーションを受けているテンプレートDNAを示しています。
TruPath Genomeは、近接マップリードテクノロジーによりカバレッジを向上させ、高精度のバリアント検出と前例のないシンプルさを実現するとともに、ヒト生殖系列全ゲノムシーケンス (WGS)を可能にします。フローセル上でのライブラリー調製により、シーケンス前の標準的なライブラリー調製が不要になります。
高精度で包括的なヒト生殖細胞系列全ゲノムシーケンス。
NovaSeq Xシリーズは、生産規模でデータ集約型アプリケーションを実行するために、卓越したスループットと精度を提供します。
DRAGEN Germlineは、全ゲノム、全エクソーム、およびターゲットパネルNGSデータ向けの精確で効率的な (FASTQからVCFまでの) 二次解析ソリューションです。
Emedgeneソフトウェアは、説明可能なAIと自動化により、希少疾患のゲノミクスやその他の生殖系列研究アプリケーションのバリアント解釈を合理化します。
近接マップリードテクノロジーに関する見解
Rady Children's Institute for Genomic MedicineのDr Stephen F. Kingsmoreが、近接マップリードテクノロジーと、それが希少な遺伝性疾患の迅速な全ゲノムシーケンス(WGS)に与える潜在的な影響に関する見解を述べます。

WGSの未来を描く
GeneDxのDirector of Laboratory Innovation TeamであるDr Joseph Devaneyは、データを比較し、近接マップリード(旧称:コンステレーション)テクノロジーの潜在的な影響に関する見解を明らかにしています。

マップリードテクノロジーによる解析の実施
イルミナのアッセイ研究開発担当アソシエイトディレクター、Louise Fraser PhDが、マップリードテクノロジー(旧称コンステレーションマップリード)のしくみと実行できる分析の種類について説明します。
ウェビナー
イルミナはAGBT 2026で、ゲノムシーケンス、マルチオミクス、ライブラリー調製、シーケンスシステム、データ解析、AIにおけるイノベーションにスポットライトを当てています。TruPath Genome、ワークフローのイノベーション、戦略的パートナーシップについては、このオンデマンドウェビナーをご覧ください。
NovaSeq Xシリーズでは現在、近接マップリード技術を利用できます。解析にはDRAGEN Germline二次解析パイプラインを利用し、イルミナ全ゲノム三次解析ソリューションと互換性があります。
近接マップリードとは、近傍のナノウェルのクラスターからの近接情報と組み合わされた標準ショートリードであり、精確な長距離ゲノムの洞察を生成します。このワークフローにより、元の長いDNAテンプレートとその結果得られるショートリードとの関連性が維持され、構造多型の検出、遺伝的バリアントの超長期フェージング、ゲノムのマッピングが困難な領域での解像度の向上が可能になります。
いいえ、実験ワークフローではシーケンスシステムの変更は必要ありません。この手法に必要なのは、新しいシーケンスレシピだけで、研究者は容易にアクセスできます。
ロングリードシーケンスにより、完全型のロングDNA分子のシーケンスが可能になります。マップリードテクノロジーワークフローでは、ロングテンプレートDNAがパターン化フローセルに直接適用され、近位のナノウェルで同じテンプレートからのDNAを含む確度が高くなります。リードは、大きな構造的バリエーションの検出、低複雑性の領域のマッピング、バリアントの超長期フェージングを含むアプリケーションに対して、高い信頼性でインフォマティクスにマッピングできます。
リードマッピングは、シーケンスリードの元となるゲノム位置を決定するプロセスを示します。アライメントは、2つ以上のシーケンス間における類似性の同定を含みます。例えば、1つのリードはゲノムの複数の場所にアライメントできますが、精確にマッピングできるのは1つだけです。マップリードテクノロジーは、リファレンスゲノムのマップリードとアライメント解析の両方をサポートします。

ゲノムの複雑な領域に関するより深い洞察を提供
イルミナのCTO兼研究&製品開発責任者のSteve Barnard博士が、Illumina TruPath Genomeを用いて取り組むべき研究課題について概説します。

隣接するナノウェルのオンフローセルライブラリー調製と近接情報が、どのように長距離ゲノムの洞察を可能にするかをご覧ください。
ポスター

機械学習とマップリードのコロケーション解析を使用して、複雑な構造的再構成を特定します。
ポスター
ヒトゲノム全体を偏りなく把握し、ヒト形質や疾患をコードする遺伝的バリアントを評価します。
ゲノミクスは、希少疾患の根底にある遺伝的バリアントの理解における、根本的な変化をもたらしています。
反復性の高い領域、大きな反転、転座など、ゲノムの複雑な領域に関する深い洞察が得られます。
NGSソリューションにより、複雑なゲノム領域全体における精確で簡便な構造多型検出が、どのように実現されるかをご覧ください。
TruPath Genomeの原動力となる近接マップリードテクノロジーが、長距離のゲノム情報と新しい洞察の解明にどのように役立つかをご覧ください。
参考文献