シーケンスワークフローの精度
イルミナシーケンスワークフロー全体の精度
典型的なシーケンスワークフローには、サンプル/ライブラリー調製、クラスター増幅、DNAシーケンス、イメージ解析/ベースコーリング、リードアライメント、バリアント探索が含まれます。これらのステップのいずれかの品質が悪いと、最終データセットの品質が損なわれます。
イルミナシーケンスでは、このプロセスの各ステップが最適化され、幅広いアプリケーションにわたって精確なデータを提供します。ライブラリー調製は特に重要なステップです。TruSeqやその他の高品質なイルミナライブラリー構築テクノロジーを使用すると、あらゆる研究プロジェクトで高いサンプル品質と精度を確保できます。
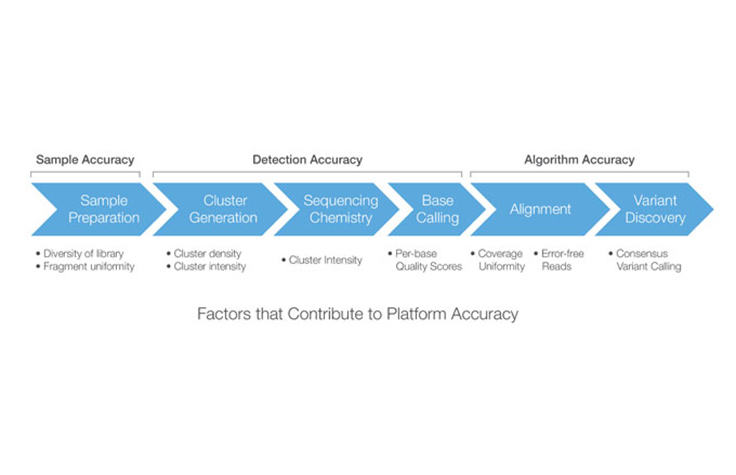
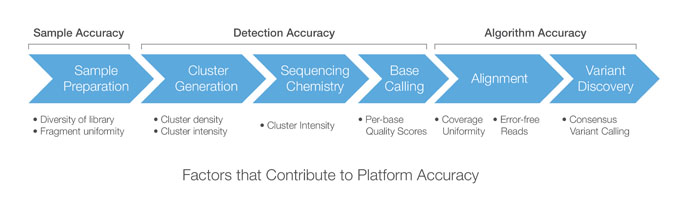
イルミナのシーケンスワークフローの各ステップの精度に影響を与える要因
プラットフォームの精度
プラットフォームの精度は、サンプル/ライブラリー調製からバリアント探索までのプロセスの各ステップを構成するシーケンスワークフローの全体的な精度を示します。シーケンスワークフローは3つの主なステージに分割でき、それぞれが独自に精度に影響します。サンプル/ライブラリーの精度、検出の精度、およびアルゴリズムの精度

シーケンステクノロジーの動画
動作中のSBSテクノロジーを見る
サンプル/ライブラリーの精度
サンプルの精度は、シーケンスワークフローのライブラリー調製ステップに関連します。この段階では、DNAはライブラリー構築のために断片化されます。ライブラリー内の各断片は最終的にシーケンスリードに対応するため、ゲノム全体の均一なカバレッジを達成するためには、断片サイズの高い均一性とライブラリーの多様性が重要です。
多様ではないライブラリーによる断片の欠損など、ライブラリー調製中に発生するエラーは、シーケンサーでは特定できません。ライブラリーにないゲノム部分はシーケンスされず、データセットにギャップが生じます。
さらに、シーケンスシグナルがクリーンでエラーのないように見えるため、クオリティスコアはこのステップ中に生じたエラーを反映しません。ほとんどのシーケンスプラットフォームで実現可能な最大精度は、サンプル精度によって制限されます。
そのため、TruSeqやその他のイルミナのテクノロジーなど高品質のライブラリー構築ソリューションを利用することが非常に重要です。
精確なライブラリー調製テクノロジー
TruSeqテクノロジーとも呼ばれる当社のアダプターライゲーションライブラリー調製テクノロジーは、長年、その高いカバレッジ均一性、精確なストランド情報、信頼性で定評があります。現在はさらに改良されました。最近のイノベーションにより、精製、サンプル移送、ピペット操作のステップ数が減少し、ワークフローの効率が向上しました。
アダプターライゲーションの詳細はこちら
イルミナシーケンスワークフロー
ライブラリー調製、シーケンス、データ解析というイルミナシーケンスワークフローのステップについて説明します。NGS実験の計画方法とワークフローの例をご覧ください。
詳細はこちら
TruSeq製品
TruSeqキットは、ライブラリー調製にシンプルさ、利便性と信頼できる結果を提供します。マスターミックス試薬とシンプルで自動化しやすいワークフローにより、ハンズオンタイムが最小限に抑えられ、ヒューマンエラーが軽減されます。定評のあるTruSeqライブラリー調製製品として以下の製品が挙げられます。
その他のTruSeq製品やイルミナのライブラリー調製オプションについては、ライブラリー調製キットの一覧ページをご覧ください。
TruSeqライブラリー調製のベストプラクティス
TruSeqライブラリー調製および濃縮プロトコールを実行するための推奨ベストプラクティスをご覧ください。
2種類のRNAライブラリー調製キットの比較
2つの定評のあるRNAライブラリー調製キットの厳密な比較から、RNAシーケンス研究を行う研究者にとって興味深い新しい情報が明らかになります。
インタビューはこちら
検出の精度
検出の精度は、シーケンスワークフローの第2段階であり、クラスター形成、DNAシーケンス、および一次データ解析で構成されます。通常、この段階で発生したエラーは、クオリティスコアに反映されます。
検出エラーは、サンプルエラーとは異なり、確立された塩基ごとのクオリティスコアを使用して追跡できます。
検出エラーは、再シーケンス、シングルリードエラー補正、またはエンコーディングスキームによって改善できます。
クオリティスコアの詳細はこちらアルゴリズムの精度
アルゴリズムの精度は、ワークフローの二次データ解析フェーズに関連し、通常はアライメントとバリアントコーリングが含まれます。アライメント手法の精度は非常に重要です。
シーケンス装置から得られるデータの品質がどれほど高くても、アライメントが最適でないと、最終データセットの品質が低下し、誤ったミスマッチの配置、不均一なカバレッジ、大量のギャップが発生する可能性があります。その結果、高い偽陽性率と偽陰性率につながる可能性があります。バリアントコーリング手法自体も、同じ理由で高精度である必要があります。
イルミナは、研究者が精確なアライメントとバリアントコーリングを実行できるよう、使いやすいバイオインフォマティクスツールを提供しています。
バイオインフォマティクスツールの詳細