シーケンスカバレッジ
NGSのカバレッジとは?
次世代シーケンサー(NGS)カバレッジは、既知のリファレンス塩基にアラインする、"または"カバーするリードの平均数を示します。シーケンスカバレッジレベルは、特定の塩基位置である程度の信頼度でバリアントの発見が可能かどうかを決定することがよくあります。
下記の通り、シーケンスカバレッジはアプリケーションごとに要件が異なります。カバレッジレベルが高いほど、各塩基はより多くのアライメントシーケンスリードでカバーされるため、塩基コールはより高い信頼度で行うことができます。
シーケンスカバレッジの推奨
必要なNGSカバレッジのレベルについて判断する際、研究者は一般的に自身が利用している手法に加えて、リファレンスゲノムのサイズ、遺伝子発現レベル、特定の関心のあるアプリケーション、既報文献、サイエンスコミュニティのベストプラクティスといったその他の要素を考慮します。下記に、一般的な手法向けのシーケンスカバレッジの推奨の例をご紹介します。
| シーケンス法 | 推奨カバレッジ |
|---|---|
| 全ゲノムシーケンス(WGS) | ヒトWGS向けには30×から50×(アプリケーションと統計モデルに応じて) |
| 全エクソームシーケンス | 100× |
| RNAシーケンス | 通常、サンプリングされる数百万リードの数で計算されます。発現が希少な遺伝子の検出には、一般的にカバレッジ深度を高める必要があります。 |
| ChIP-Seq | 100× |

望ましいNGSカバレッジのレベルの判断と実現の方法
シーケンスランの判断:
Lander/Watermanの式1がゲノムカバレッジの計算手法です。一般的な方程式は次のとおりです。C = LN / G
- Cはカバレッジを表します
- Gは半数体ゲノム長
- Lはリード長
- Nはリード数
サイエンティストによるカバレッジ判断の一助として次のリソースを提供します:
- シーケンスカバレッジカルキュレーター:実験に必要なシーケンスカバレッジを達成するために必要な試薬とシーケンスランの計算方法をご覧ください
- RNA-Seqリード長とカバレッジ:さまざまなRNA-Seqプロジェクトにおけるシーケンスリード深度ガイドラインの詳細 はこちら
シーケンスを強化する必要がある場合
データがさらに必要な場合にはカバレッジやシーケンスの深度を増やすことができます。必要に応じて、当初のサンプルとともに、さまざまなフローセルからのシーケンス出力を組み合わせます。当初判断したカバレッジ以上にシーケンスが必要となる理由は:
- アッセイに統計的検出力を追加
- 非常に希少な事象を調査するため
- ジャーナルまたはフィールドの最低カバレッジしきい値を満たす
- シーケンス困難領域または多倍体ゲノムのシーケンスのため
NGSカバレッジの範囲と均一性を説明するヒストグラム
カバレッジヒストグラムは通常、データセット全体のシーケンスカバレッジの範囲と均一性を示すために使用されます。マップされたシーケンスリードでカバーされるリファレンス塩基数をさまざまな深度で表示することで、全体的なカバレッジ分布を図示しています。マッピングされたリード深度とは、特定のリファレンス塩基位置でシーケンスおよびアライメントされた塩基の総数を指します("マッピング"および"アライメント"された塩基はシーケンスコミュニティで互換的に使用されます)。
シーケンスカバレッジヒストグラムでは、リード深度はX軸にビニングされ、表示されます。一方、各リード深度ビンを占有するリファレンス塩基の総数はY軸に表示されます。これらはリファレンス塩基のパーセンテージとして記述することもできます。
カバレッジのヒストグラムの例
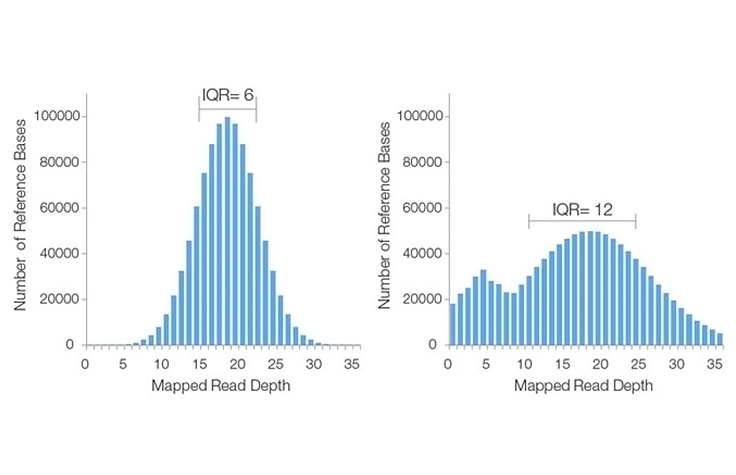
理想的には、このヒストグラム画像に示されているように、プロットは若干の標準偏差を伴ったポアソン近似の分布を示します。この分布は、リードがゲノム全体においてランダムに分布し、リード間の実際の重複を検出できる能力がシーケンスランにおいて一貫しているという想定の下で有効です。
ただし、さまざまな理由から、実際のカバレッジヒストグラムには大幅な開きがあるか(つまり、リード深度の範囲が広い)、ポアソンではない分布になる場合があります。右に示した不十分なシーケンスカバレッジのヒストグラムの例の通りです。
次世代シーケンサー(NGS)カバレッジの評価
NGSカバレッジの評価について一般的には次のメトリクスが利用されています:
四分位数範囲(IQR)
IQRは、ヒストグラムの75パーセンタイルと25パーセンタイルのシーケンスカバレッジの差です。この値は統計的変動の尺度であり、データセット全体のカバレッジの不均一性を反映しています。
高いIQRはゲノム全体のカバレッジのばらつきが大きいことを示し、低いIQRはより均一なシーケンスカバレッジを反映しています。上記のヒストグラムの例では、低いIQRは、左側のヒストグラムが右側のヒストグラムよりもシーケンスカバレッジの均一性が高いことを示しています。
中央値(マッピング済み)リード深度
マップされたリードの平均深度(または平均リード深度)は、各リファレンス塩基位置のマップされたリード深度の合計をリファレンスの既知の塩基数で割った値です。
平均リード深度メトリクスは、特定のリファレンスベース位置でアライメントされるリードの平均数を示します。
生リード深度
これは、装置が生成したシーケンスデータ(アライメント前)の合計量をリファレンスゲノムサイズで割った値です。生のリード深度は、シーケンス装置のベンダーによって仕様として提供されることがよくありますが、アライメントプロセスの効率は考慮されていません。
アライメントプロセス中にローシーケンスリードの大部分が廃棄された場合、アライメント後にマッピングされたリード深度はローリード深度よりも大幅に小さくなります。
Interested in receiving newsletters, case studies, and information from Illumina based on your area of interest? Sign up now.
参考文献
- Lander ES, Waterman MS. ランダムクローンのフィンガープリントによるゲノムマッピング:数学的解析。Genomics. 1988;2(3):231-239. doi:10.1016/0888-7543(88)90007-9